




Peer review is one of the most important parts of running a conference, symposium, or call for papers. It is also one of the most time consuming.
Program committees often spend days assigning submissions, balancing reviewer workloads, checking topic fit, and trying to maintain consistency across thousands of abstracts.
Human reviewers remain central to the process, of course, but there is now a smarter way to support them. We have introduced a new feature in Dryfta called AI Reviewers.
This new capability lets organizers create up to three Virtual Reviewers inside the review workflow. These Virtual Reviewers behave like reviewer profiles in your system, can be configured like human reviewers, and can submit advisory reviews based on the settings and expertise defined in their profile.
The result is a review process that becomes faster, more structured, and easier to manage, while still keeping human judgment at the center.
What are AI Reviewers?
Inside Dryfta’s Abstract Submission Software, event admins will now find a new option to enable AI Reviewers.
Once enabled, you can choose how many Virtual Reviewers you want to create, up to three. Each one is added to the Reviewers list just like a normal reviewer profile. They can also be deleted if no longer needed. Each Virtual Reviewer can be configured with its own review identity, including:
- areas of expertise
- submission type preference
- language preference
- reviewer affiliation
That means a Virtual Reviewer can be tuned to behave like a reviewer with a specific background. For example, if a profile is configured for French language submissions and Biology related topics, it will evaluate abstracts through that lens.
This makes the AI review process more contextual and far more useful than a generic one-size-fits-all assessment.
How Virtual Reviewers work
When Virtual Reviewers are first created, Dryfta assigns all topics, tracks, and submission types to them by default. This ensures they are ready to participate immediately.
From there, admins can go into each Virtual Reviewer profile and refine the setup. You can narrow topic expertise, adjust preferred submission types, set language preferences, and map other relevant profile fields depending on how detailed your review structure is.
Once configured, Virtual Reviewers are assigned submissions based on the same profile logic you would expect from a human reviewer, such as:
- topic and subtopic expertise
- job title or professional background
- affiliation
- submission type preference
- language preference
- other mapped profile criteria
This gives organizers more control over how AI is applied. It is not simply reviewing everything blindly. It is reviewing according to the profile you define.
Another key difference is that human reviewer workload limits do not apply to Virtual Reviewers. Even if your human reviewer pool has reached its assignment cap, Virtual Reviewers can still be assigned so every submission can receive an advisory AI assessment.
This is especially helpful during heavy submission periods, last minute review cycles, or events with limited reviewer availability.
Virtual reviews are advisory only
One of the most important parts of this feature is how carefully it has been designed to support, not override, human decision making.
Dryfta keeps human and virtual review scores strictly separate. Virtual reviews:
- do not alter the overall abstract rating
- do not get merged into the human score
- are used as advisory input only
This means organizers and program committees can benefit from AI-generated feedback without compromising the integrity of the formal human review process. It allows scientific committees to modernize the workflow without creating concerns about fairness, governance, or over reliance on automation.
Virtual Reviewers can abstain when appropriate
Like a good reviewer should not be forced to score content they are not qualified to assess, the same principle applies here. Virtual Reviewers in Dryfta are not required to review every assigned submission. They first scan the submission and determine whether it is appropriate to review.
If the content is weak, incomplete, irrelevant, or outside the reviewer’s configured capability, the Virtual Reviewer can abstain and submit a comment instead.
By allowing abstention, Virtual Reviewers behave more like responsible reviewers and less like automatic scoring bots.
Reviews are submitted through the normal review form
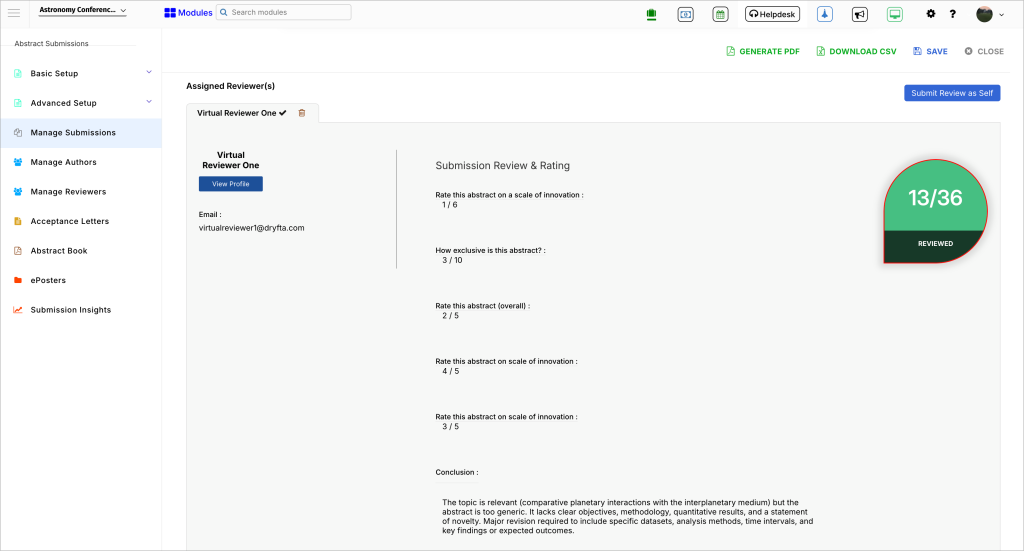
Another strength of this feature is that Virtual Reviewers submit their feedback through the same review submission form used by human reviewers.
That means they answer your existing review questions, follow your scoring structure, and save their review data in the same review database architecture as standard reviewer data.
This creates several practical benefits:
- First, there is no separate interface to learn.
- Second, organizers can compare virtual and human input more easily.
- Third, the AI review process fits naturally into existing conference workflows rather than forcing teams to rebuild them.
For organizers, this means you can turn on AI assistance without disrupting the review framework your committees already trust.
Separate displays for virtual and human ratings
To make comparison easier, Dryfta now includes separate list view columns for:
- cumulative rating from Virtual Reviewers
- cumulative rating from Human Reviewers
This gives admins and program managers a clearer view of how submissions are being assessed from both angles.
Instead of blending everything into a single abstract score, the platform shows where the advisory AI opinion stands and where the human reviewer consensus stands.
It helps highlighting cases where the two differ sharply, which may signal that a submission deserves another look, a senior reviewer check, or discussion by the scientific committee.
AI Reviewers: Why this matters for conference organizers?
Most event teams are not looking to remove humans from peer review. They are looking to reduce bottlenecks, improve consistency, and make better use of limited reviewer time. That is exactly where AI Reviewers help.
1. Faster review support at scale
When submission volume grows, human reviewers can quickly become overloaded. Virtual Reviewers make it possible to add advisory assessments across all submissions without being constrained by human workload caps.
2. Better early detection of weak submissions
Low quality abstracts, irrelevant submissions, and unsupported language cases can be flagged earlier in the process. This saves time for program teams and human reviewers.
3. More contextual AI feedback
Because Virtual Reviewers are shaped by profile settings such as topic expertise, language, and reviewer role, their feedback is more relevant and less generic.
4. Stronger quality control without sacrificing human oversight
AI reviews remain separate and advisory only. Human committees keep control of official scoring and final decisions.
5. Easier comparison and triage
With separate cumulative columns for human and virtual ratings, organizers can quickly spot alignment, disagreement, and submissions that may need manual attention.
Use Case
Imagine you are running a large academic conference with several hundred abstracts spread across multiple tracks and languages.
You create three Virtual Reviewers: Each Virtual Reviewer is assigned submissions based on its configured profile. One reviews appropriate abstracts and submits structured advisory feedback through the review submission form. Another abstains on a submission because the content falls outside its expertise. A third flags a weak abstract with placeholder content.
Meanwhile, your human reviewers continue their normal work, and their scores remain the only scores that affect the official abstract rating.
Now your committee has more context, faster screening, and clearer visibility, without changing the integrity of the review process.
Built for real conference workflows
AI features often sound exciting in theory but fail in practice because they do not respect how review workflows actually work.
Dryfta’s AI Reviewers are built around the needs of program managers, scientific committees, and conference administrators who need practical help, not black box automation.
You stay in control of:
- how many Virtual Reviewers to create
- how each one is configured
- which expertise areas and preferences they represent
- how their feedback is used
- how human and virtual ratings are viewed side by side
This makes the feature flexible enough for academic conferences, association events, call for papers workflows, and other submission driven programs where structure and accountability matter.